Overview
딥러닝 모델 중 Autoencoder에 대해서 알아볼 것입니다. Autoencoder는 입력값만으로 학습하며 비지도학습입니다. 이와 관련하여 잡음을 제거해 데이터 복원하기까지 학습하도록 하겠습니다.
이 글은 “팽귄브로의 3분 딥러닝, 파이토치맛”을 읽으면서 작성되었습니다.
예제 출처는 다음과 같습니다.github
1. Autoencoder란
2. 오토인코더로 이미지의 특징 추출하기
3. 오토인코더로 망가진 이미지 복원하기
4. 마치며
Autoencoder란
- Autoencoder는 비지도 학습으로 라벨링 없이 입력 데이터만으로 학습을 합니다.
- 입력 데이터도 X이고 출력 데이터도 X 입니다.
- 입력 데이터를 압축하고, 복원을 합니다.
- 압축과 복원하는 부분을 나누어 인코더(encoder), 디코더(decoder)라고 합니다.
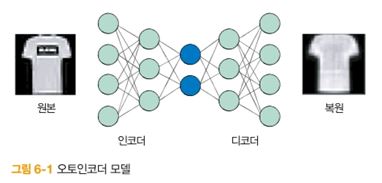
- 인코더를 거친 입력 데이터에 대한 특징을 알아낼 수 있습니다.
- 압축과 복원 과정에서 데이터가 손실이 발생합니다.
오토인코더로 이미지의 특징 추출하기
오토인코더는 크게 인코더, 디코더로 나누어집니다. 그래서 표현하면 다음과 같습니다.
kaggle link
전체코드는 아래 링크에서 가져왔습니다.
예제 출처는 다음과 같습니다.github
Code Reivew
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 12),
nn.ReLU(),
nn.Linear(12, 3), # 입력의 특징을 3차원으로 압축합니다
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(),
nn.Linear(12, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28*28),
nn.Sigmoid(), # 픽셀당 0과 1 사이로 값을 출력합니다
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
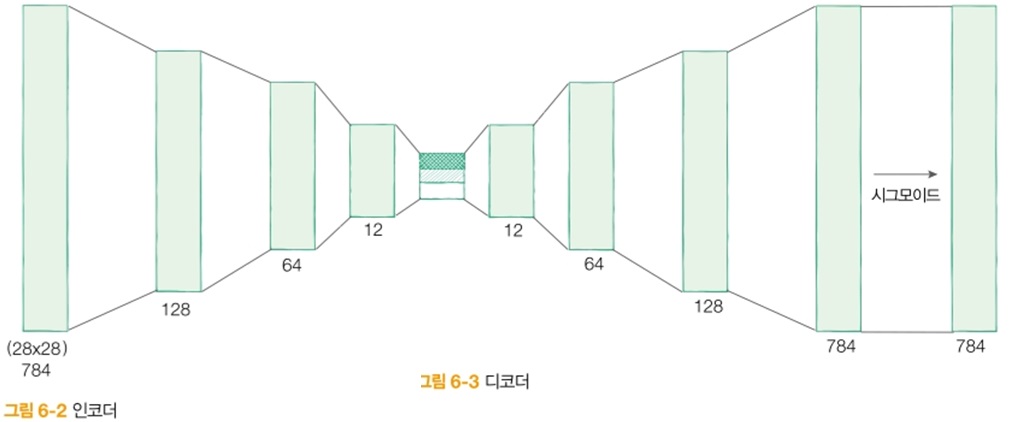
인코더의 경우 2828을 입력을 받아 3인 출력의 데이터의 특징을 받습니다.
반대로 디코더의 경우 3의 입력을 받아 2828 출력을 받습니다.
손실함수의 경우 결과 값에 일치여부를 판단한 것에 대한 손실을 계산하는 것이 아닌 입력에 대한 손실율을 계산을 합니다.
그에 따라 평균제곱오차(mean squared loss)를 이용하여 손실율을 계산합니다.
그리고 Adam 최적화 알고리즘을 사용합니다. 가중치에 대한 자료
autoencoder = Autoencoder().to(DEVICE)
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=0.005)
criterion = nn.MSELoss()
이후 학습을 하고 학습 결과를 살펴보았습니다.
# 원본 이미지를 시각화 하기 (첫번째 열)
view_data = trainset.data[:5].view(-1, 28*28)
view_data = view_data.type(torch.FloatTensor)/255.
def train(autoencoder, train_loader):
autoencoder.train()
for step, (x, label) in enumerate(train_loader):
x = x.view(-1, 28*28).to(DEVICE)
y = x.view(-1, 28*28).to(DEVICE)
label = label.to(DEVICE)
encoded, decoded = autoencoder(x)
loss = criterion(decoded, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
for epoch in range(1, EPOCH+1):
train(autoencoder, train_loader)
# 디코더에서 나온 이미지를 시각화 하기 (두번째 열)
test_x = view_data.to(DEVICE)
_, decoded_data = autoencoder(test_x)
# 원본과 디코딩 결과 비교해보기
f, a = plt.subplots(2, 5, figsize=(5, 2))
print("[Epoch {}]".format(epoch))
for i in range(5):
img = np.reshape(view_data.data.numpy()[i],(28, 28))
a[0][i].imshow(img, cmap='gray')
a[0][i].set_xticks(()); a[0][i].set_yticks(())
for i in range(5):
img = np.reshape(decoded_data.to("cpu").data.numpy()[i], (28, 28))
a[1][i].imshow(img, cmap='gray')
a[1][i].set_xticks(()); a[1][i].set_yticks(())
plt.show()

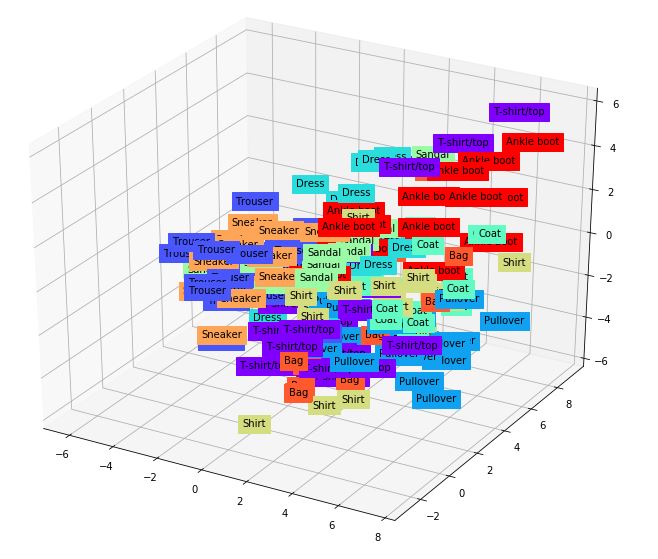
학습 결과로부터 특징점 분석
오토인코더의 학습 결과를 확인하면 출력데이터 3개를 3차원 plot으로 그린 결과가 아래와 같습니다.
이를 통해 학습을 통하여 동일한 특징의 데이터들이 모이는 것을 알 수 있습니다.
- 오토인코더를 활용하여 데이터를 복원할 수 없는 데이터인 경우 이상점인 것을 찾아내는 방법이 있다고 합니다.
오토인코더로 망가진 이미지 복원하기
잡음 제거 오토인코더는 해당 논문에서 처음 제안됐다고 합니다.
- 오토인코더는 일종의 압축입니다.
- 그에 따라 데이터 특성에 따라 우선순위를 매기고 낮은 순위의 데이터를 버린다는 뜻입니다.
- 여기서 낮은 순위의 데이터는 잡음을 의미합니다.
- 즉, 잡음이 있더라도 복원 시 잡음이 제거되는 것이 오토인코더의 특성 입니다.
Code Review
kaggle link
전체코드는 아래 링크에서 가져왔습니다.
예제 출처는 다음과 같습니다.github
여기서 위의 코드와 다른 점은 학습 시 무작위 잡음을 이미지에 더해줍니다.
def add_noise(img):
noise = torch.randn(img.size()) * 0.2
noisy_img = img + noise
return noisy_img
def train(autoencoder, train_loader):
autoencoder.train()
avg_loss = 0
for step, (x, label) in enumerate(train_loader):
noisy_x = add_noise(x) # 입력에 노이즈 더하기
noisy_x = noisy_x.view(-1, 28*28).to(DEVICE)
y = x.view(-1, 28*28).to(DEVICE)
label = label.to(DEVICE)
encoded, decoded = autoencoder(noisy_x)
loss = criterion(decoded, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item()
return avg_loss / len(train_loader)
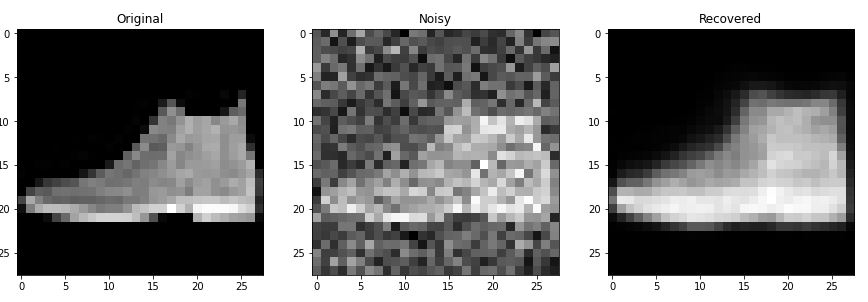
학습결과를 보면 아래 이미지와 같습니다.
마치며
읽어주셔서 감사합니다. 비지도학습 Autoencoder에 대하여 간단하게 알아보았습니다.
{kind=link}